A Tale of Terraform and Atlantis at Grabyo


As a Senior DevSecOps engineer at Grabyo, I can’t help but appreciate the irony portrayed in the comic above. Despite the expanding nature of the role, our team’s primary objective remains the same: balancing infrastructure cost, security, and quality across the company.
In an ideal scenario, we exist behind the scenes, available to help dev teams make infrastructure decisions when needed while also supplying tools and processes that allow them to safely build quality software quickly.
So, how do we achieve this at Grabyo?
We focused on developer experience and combined Terraform (IAC), Github (SCM) and Atlantis (IAC automation) to make it as easy as possible for infrastructure changes to be safely applied with minimal manual intervention.
The Lay of the Land
This blog will be getting into the nitty gritty of how we’ve configured these tools to best suit our needs, but to do that we need to broadly cover how we organise our infrastructure.
We’ve built Grabyo from the ground up to be cloud-native, specifically tying into AWS as our cloud provider. Below is a vastly simplified overview of our account structure:
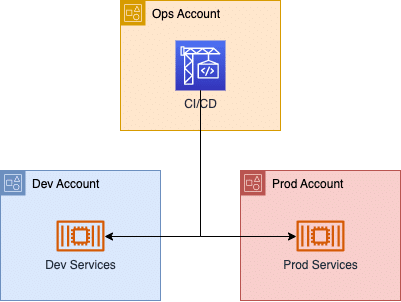
We also follow a microservices architecture, with each service having its own GitHub repository. Within each repository is the source code for the service as well as the Terraform configuration for its infrastructure.
The Age of Manual Labour
Initially, when working with Terraform in this manner, the workflow for developers resembled the following:
- Raise a Pull Request (PR) with a locally generated plan
- Once approved, locally apply the changes
- Merge in the changes
The Problems
This workflow, while logically quite simple, opened up a whole range of issues. While individually manageable, these issues escalated in proportion to Grabyo’s size and were particularly prevalent in our most actively developed (i.e. critical) services.
- Manual Plan Attachment: This workflow required developers to manually attach a plan to their PR for approval by the DevOps team. If there were other PR’s with changes in progress, or with conflicting changes, then we would often need to discuss either combining the infrastructure changes or “queuing” them to minimise risk of mistakes.
- Permission Issues: Not everyone had permission to apply Terraform changes, leading to a dependency on senior team members to perform these actions. This created bottlenecks and slowed down the development process. Furthermore, it added pressure on us to routinely increase developer permissions (an anti-pattern when considering the Principle of Least-Privilege).
- Conflicts and Lack of Visibility: There were instances where conflicts arose because the plan reviewed by one person was not necessarily the plan that was applied. This lack of visibility into applied plans made it difficult to track changes and identify discrepancies between what was reviewed and what was actually deployed.
- Complex State Management: At the time, Terraform didn’t support importing, moving or removing objects from state via configuration. All of these types of actions had to be performed manually and directly against the shared state file that other developers were referencing. This in turn compounded the previous issues, as it would temporarily lead to drift between configuration and state.
Transitioning to Atlantis Automation
To resolve these problems, we investigated a number of different automation solutions. Spoiler – the winner of these was Atlantis, but below are the reasons why we didn’t choose another tool:
- Terraform Cloud – Deemed too expensive at the time of deciding.
- In house automation (e.g. Jenkins pipelines) – In-house solutions tend to be more effort than they are worth, especially within a small company. Often leads to shortcuts being taken that sting us in the long run.
- GitHub Actions – Almost won, but misses the locking feature provided by Atlantis, the workflow wasn’t as smooth as the “ChatOps” style of Atlantis and the cost was the final straw.
Having made that decision, we set up our Atlantis container and integrated it into the development workflow. The workflow, as outlined on Terraform Pull Request Automation | Atlantis, appears as follows:
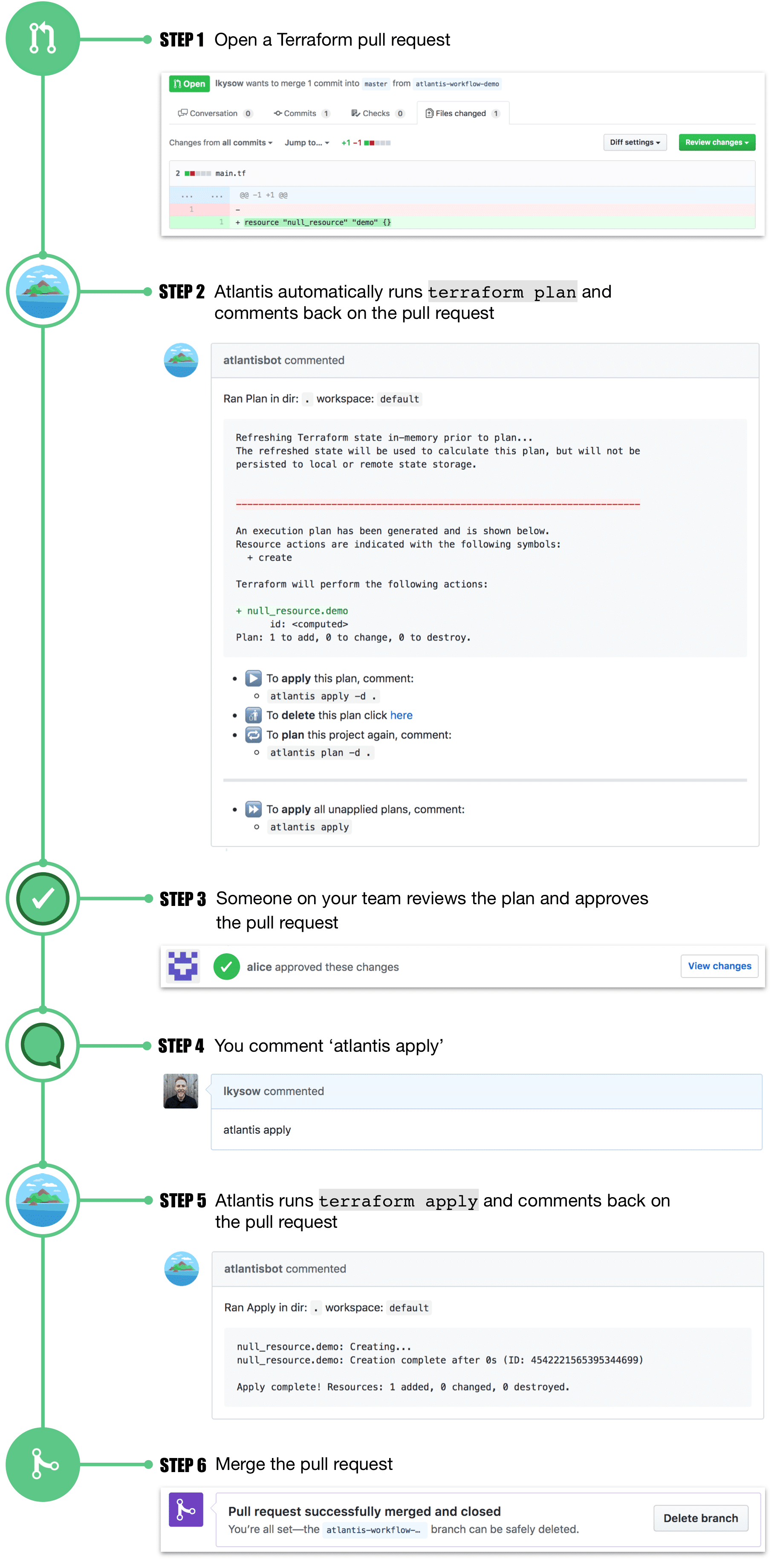
What did this solve?
With this new setup, we can review the problems it was able to solve for us:
- Manual Plan Attachment: Atlantis now generates these plans for us every time a PR is updated. The only thing we needed was to include an atlantis.yaml file to nudge it in the right direction.
- Permission Issues: We combined Atlantis with GitHub Codeowners to enforce that every PR where
*.tffiles were modified must be reviewed by a Senior DevSecOps engineer. Then, once approved, Atlantis has the relevant permissions to apply the changes on behalf of the developer. This means that developers temporarily elevate their permissions when needed, without needing their day to day permissions to be permanently changed. Admittedly, there are still other security considerations raised by this solution, and those will be discussed later. - Conflicts and Lack of Visibility: Conflicts are resolved by Atlantis locks. These in effect create a queue of one PR being resolved at a time when it comes to infrastructure changes. This way, we’re able to much more clearly manage which changes take place when, and avoid any race condition scenarios. The lack of visibility is solved by every Terraform change being captured within the PR conversation itself.
- Complex State Management: Atlantis exposes some of the state management commands directly (e.g. atlantis import) but also allows users to provide additional flags directly to Terraform. That way, state management is performed in full visibility (and also only after review and if the PR has obtained the lock discussed previously). That said, in more recent Terraform versions, state management actions can be included within the configuration themselves, saving the need to run them separately (e.g. terraform import blocks).
Permission Management
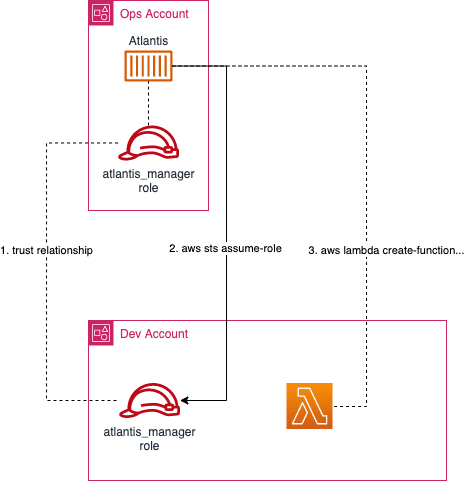
Centralizing deployment permissions with Atlantis could have potentially granted it extensive permissions within our AWS accounts. To help mitigate this, we include some explicit “deny” statements around particularly destructive actions (e.g. ec2:DeleteVpc). For the rare cases where we may want to still perform those actions, we currently revert back to applying changes locally (generally requiring the involvement of a senior engineer). This allows us to still use Atlantis the majority of the time (speeding up development) while still forcing riskier changes to be performed manually with increased oversight.
In addition, we are still beholden to a Senior DevSecOps engineer approving every single infrastructure change. Currently, this is not too much of a burden on our time and we don’t run into many cases where we are a bottleneck due to lack of resourcing, however this required review process isn’t likely to be scalable long term.
Ideally, to solve the resourcing problem, and stop Atlantis having “sudo-esque” AWS access, we would have Atlantis choose more fine grained permissions dependent on context. We explored this previously, with work into Attribute-Based Access Controls (ABAC), but ran into too many edge cases for it to be deemed viable at the time. We may return to this in the future as Grabyo continues to grow.
Maintainability
As mentioned previously, each of our microservice repositories manages its own IAC. This opened up a few challenges:
- How can we avoid IAC duplication
- How do we share best practice?
- How do we keep IAC up to date?
For common resource patterns, we create our own Terraform remote modules. These are created and updated by DevSecOps with our best practices, and are written to be as easy as possible for other teams to use. That way, we have a type of “security by convenience” as these modules are chosen by teams because they save development time and offer the security features as a bonus.
To keep things up to date, we’ve been making use of dependabot. This tool, in combination with Atlantis and our remote modules, allow us to easily role out security updates across the company. For example, when AWS introduced Origin Access Controls for Cloudfront we were able to roll it out in the following way:
- Update our
cloudfront-static-sitemodule - Dependabot then raised PRs for all repos using the module
- DevSecops then reviewed these PRs and merged them in
We’ve had to be thoughtful on how aggressive we configure dependabot to be (it can become very spammy if misconfigured) but it’s really helped us to build on our existing automation to keep our infrastructure up to date and secure.
Final Thoughts
In writing this, I reflected with a colleague that we really do have a good grip on how we manage our infrastructure. I’ve worked in previous roles where infrastructure changes were much harder to implement, or if they were easy to implement it was always a bit wild-west in their security (which is just begging for trouble).
I hope this blog has helped to give you an insight into our processes, in addition to some specific technical solutions that you might be able to bring in to your own place of work!
If you have thoughts and ideas on how we could further build on this solution at Grabyo, or if you have your own workflows that we could compare to and learn from, don’t hesitate to share them with us!
Thank you for reading. Here’s a cookie for your time 🍪