How we create production-ready microservices in hours

As explained in our previous post, Our Road to Microservices, we reached a point where our engineering team understood that migrating from a monolithic to a microservices architecture would bring many improvements in our development speed.
However, when we started to put our new strategy into practice, we were constantly hitting a brick wall that stopped us from starting this journey. Our initial approach was to build new features outside the monolith to ensure we were not contributing to its growth. However, whenever a team presented a plan to build a simple feature as a new microservices, deadlines were extended (usually for an additional month), and the initiative usually ended up being turned down.
The main reason for these additional delays on features was the extra effort our teams needed to put into creating all the foundations and boilerplate code associated with any microservice.
Introducing the Java Microservice Template
Our solution to this problem was to build a production-ready microservice template that solves most of these challenges for our engineers so they can focus on writing the application logic.
Our current tech stack includes various programming languages for backend services (NodeJS, Ruby, Golang or C++). However, since this template would require significant effort from our Platform team, we decided to start with the most common language at Grabyo, Java.
When building this template, we had the following objectives:
- Enable microservices to be created quickly
- Employ a consistent CI/CD process
- Ensure consistent testing across microservices
- Share best practices around common technologies
- Provide a boilerplate app with the standard structure already present
- Finally, provide a point for continual improvement
What’s included in the template?
Let’s cover the leading technologies included in the template:
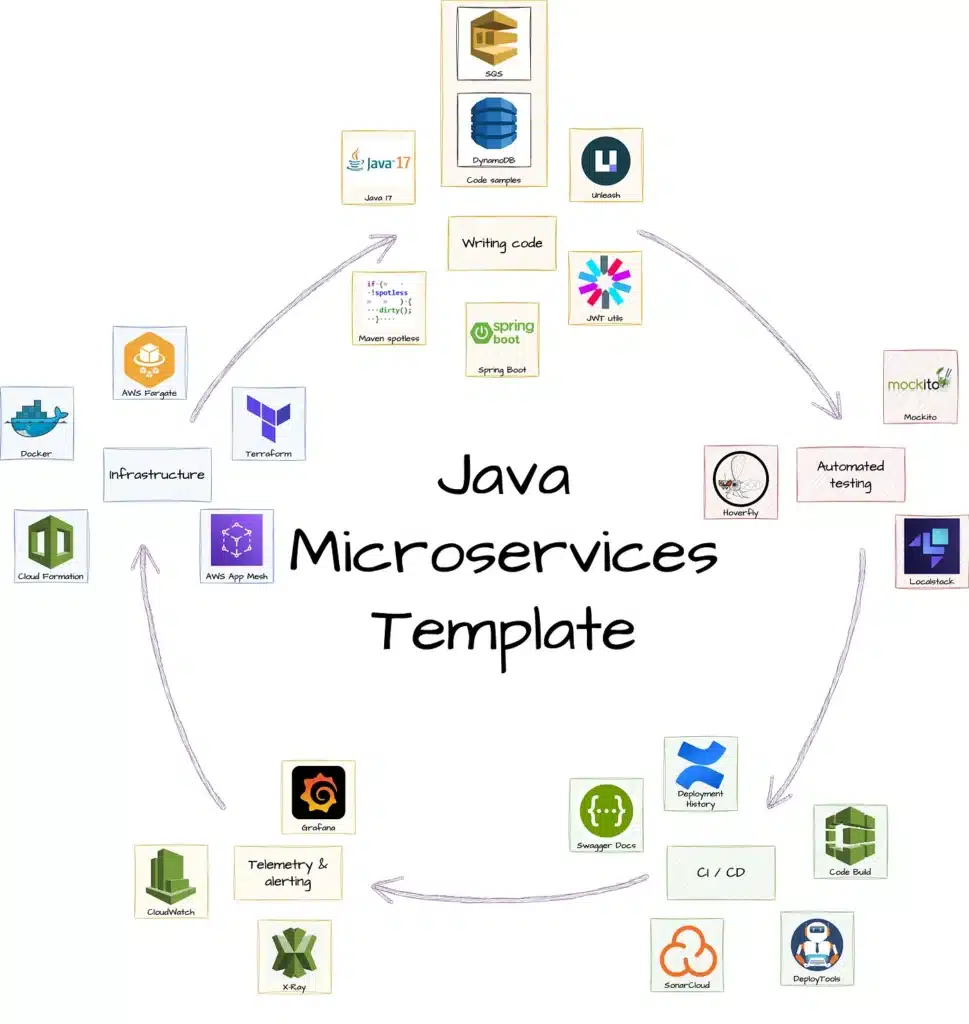
Infrastructure
The template runs inside Docker containers locally and in our multiple AWS environments on top of AWS Fargate and inside of our mesh (we use AWS App Mesh to help with our deployments), where all our microservices are deployed. In addition, the template uses IoC technologies to avoid configuration drifts. Concretely, we use Terraform for static infrastructure (i.e. load balancers, service definitions on Fargate, etc.) and Cloud Formation for dynamic infrastructure (i.e. tasks deployments inside Fargate).
Coding
As mentioned before, the template is built around Java. Concretely, at the time of writing, it runs Spring Boot and Java 17, and it provides the following tools already configured to help our developers start writing code almost out of the box:
- Running examples of common AWS services that most of our microservices use (i.e. DynamoDB and SQS)
- Unleash setup for feature management to support our engineers with trunk-based development
- Security helper libraries for authentication and authorization operations in our platform
- Maven spotless to ensure all code is appropriately linted
Testing
To ensure our engineers have great support for automated testing, we provide the following:
- Mockito to ensure we can create mocks for our unit tests
- Hoverfly to stub and simulate HTTP(S) API requests
- LocalStack to replicate common AWS services during localhost and cloud development
- DeployTools to manage our ephemeral environments for testing
DeployTools deserves its own blog post, but it would be good to cover the basic functionality provided.
DeployTools is mainly used to manage our integration tests and demo environments. Concretely, it integrates with our GitHub account and allows engineers to type GitHub comments like “deploy prod” to create on-demand environments.
These environments get shut down daily at certain times unless engineers notify the system to keep them for more extended periods (i.e. long-running tests).
CI & CD
The template includes a CodeBuild pipeline that provides the following:
- It runs all our automated tests during the CI stage
- It releases the service to production on every commit merged to the main branch
- It creates a deployment history inside our internal Confluence wiki
- It automatically generates and publishes Swagger API documentation
- Finally, it performs code analysis and publishes its results to SonarCloud for code quality management
Telemetry & alerting
To ensure our microservices are healthy, the template provides the following integration with:
- CloudWatch for metrics and remote logs.
- X-Ray to monitor performance on interservice communications.
- A basic Grafana dashboard to display basic graphs like JVM performance, API response times, CPU and memory usage, etc.
How to use the template?
The template is treated like any other microservice in the platform. It lives in GitHub, and it’s linked with our different environments. We decided to treat it as a production service to ensure all the different components are used and supported to guarantee everything works as expected when a new microservice is created. All resources are set to a minimum to reduce its costs to about $5/month.
When one of the teams requires to create a new microservice, it only needs to do the following:
- Create a fork of the existing template repository
- Ensure all infrastructure code reflects the name of the new service (i.e. renaming the Faragate service name to avoid duplicates)
- Remove any unnecessary boilerplate code (i.e. remove SQS if it’s not needed)
- Start coding!
At this point is important to highlight that the template is constantly evolving. This means that we are continually making improvements and including new features. In fact, we have clear guidelines to encourage any team to make contributions.
Because this is a template, there are some considerations to be made:
- The template does not enforce consistency across our microservices. It promotes some best practices, but every microservice can diverge from the template to include customizations that benefit the service
- When a new improvement is made in the template, other teams can only benefit from these if they manually include them in their service
- While this might look like a downside, the reality is that there are no two microservices identical, and engineers prefer to have the flexibility to change things to cater for their own needs
So what does the future hold?
The sky is the limit! However, when we first released the template with less boilerplate around AWS services (i.e. DynamoDB or SQS), our engineers spent lots of time copying over this boilerplate from other services.
With this boilerplate in place, it is much easier and faster to delete the code they don’t need (it is easier to remove unnecessary code from the template than add new code — i.e. to connect to DynamoDB).
For this reason, in the future, we would like to add more support for other common AWS services that our teams might use commonly.
Final comments
This Java Microservice Template has been a critical milestone in our journey to migrate our platform to a microservices architecture.
Before the template, creating a new microservice could take up to two months to create all the boilerplate required. We can create a new microservice in a few hours with the template now! 🚀🚀
If you are starting the migration to a microservices architecture, I would highly recommend starting here before you try to create new production-ready microservices.
Thanks for reading!
We’re hiring!
We’re looking for talented engineers in all areas to join our team and help us to build the future of broadcast and media production.