Cloud-Native Search: Our Path to a Fully Serverless Architecture

Picture this: It’s another bustling day at Grabyo, and our trusty search infrastructure is humming along, helping users find exactly what they need. But behind the scenes, our engineering team has been exchanging knowing glances. Our beloved search cluster, built on AWS ElasticSearch, has been showing its age. It’s not just the growing complexity of our data – it’s the realization that we’re running on borrowed time with a soon-to-be deprecated service.
One day, over a virtual coffee break, someone finally says what we’ve all been thinking: “Folks, it’s time for an upgrade.”
And just like that, our search infrastructure saga began. We weren’t setting out to change the world – we just wanted to tackle some much-needed improvements and set ourselves up for future success. Our mission, should we choose to accept it (spoiler: we did), was fourfold:
First on our list was giving our search cluster a well-deserved upgrade. AWS OpenSearch was calling our name, promising newer features and long-term support. But we knew it wouldn’t be a simple flip of a switch – there’d be code to refactor and libraries to update.
As we dug deeper, we realized this was our chance to address another pain point – those scheduled maintenance windows when we had to pause data ingestion. “What if,” someone mused, “we could buffer our data somehow?” And thus, our quest for queue-driven insertion began, aiming to make our system more resilient during these necessary maintenance periods.
But why stop there? Our disaster recovery strategy, while functional, had started to feel a bit like a Rube Goldberg machine – overly complex and always one script away from potential headaches. We dreamed of a more elegant solution, one that could handle our ever-growing data with grace and efficiency.
And throughout all of this planning, a common theme emerged. More and more, we found ourselves drawn to the world of serverless technologies. It felt like the right direction for Grabyo – more scalable, more manageable, more… well, more us.
So there we were, with a clear mission and a lot of work ahead. It wasn’t going to be a walk in the park, but we were excited about the possibilities. In this post, we’ll take you along on our journey – the challenges we faced, the decisions we made, and yes, even the facepalm moments (because what’s an engineering project without a few of those?).
Whether you’re contemplating your own infrastructure upgrades or just curious about what goes on behind the scenes of a search system, we hope you’ll find our story informative, and maybe even a little entertaining. So grab a coffee (or your beverage of choice), and let’s dive into the tale of how we at Grabyo nudged our search infrastructure into the cloud-native era.
The Architecture Behind Grabyo’s Search Capabilities
To understand the evolution of Grabyo’s search infrastructure, it’s crucial to start with the foundation of our data storage and retrieval system. At the core of our platform lies Amazon DynamoDB, our primary database for storing and managing data. However, while DynamoDB excels in many aspects, it lacks robust search capabilities, particularly for complex queries across multiple attributes or tables.
This limitation led us to implement OpenSearch (previously Amazon ElasticSearch) as our search engine. OpenSearch allows us to create indexes that enable fast and efficient searching across our data. These indexes are essentially optimized representations of our data, structured for quick retrieval based on various search criteria.
In our search infrastructure, we utilize two types of indexes:
- Single Indexes: These are straightforward mappings between a single DynamoDB table and an equivalent OpenSearch index. The OpenSearch index contains the same data as the DynamoDB table, allowing for quick searches on that specific dataset.
- Composite Indexes: These are more complex, combining data from multiple DynamoDB tables into a single OpenSearch index. This approach is crucial for scenarios where we need to search across attributes from different tables simultaneously, providing a unified search experience across related datasets.
In our previous architecture, data consistency between DynamoDB and OpenSearch was maintained through direct, real-time synchronization. Whenever a record was inserted, updated, or deleted in a DynamoDB table, the corresponding change was immediately reflected in the OpenSearch cluster. This approach, while straightforward, had its limitations, particularly during cluster maintenance windows.
")
Our new architecture introduces several improvements to enhance reliability and efficiency:
- For single table synchronizations:
- We now leverage DynamoDB streams to capture changes in the database.
- These change events trigger a Lambda function.
- The Lambda function sends the data to an SQS queue.
- Another Lambda function consumes from this queue and applies the changes to the OpenSearch cluster.
- For multiple table synchronizations:
- Our monolithic application retains responsibility for detecting changes.
- Instead of directly modifying the OpenSearch cluster, it now writes these changes to a dedicated SQS queue.
- A Lambda function consumes from this queue and applies the changes to the appropriate composite index in the OpenSearch cluster.
")
The introduction of this queuing mechanism is a key improvement in our system. It acts as a buffer, ensuring that no data is lost during cluster maintenance windows or in the event of temporary issues with the OpenSearch cluster. Changes are queued and processed once the cluster is available, maintaining data integrity and consistency.
This new architecture provides several benefits:
- Improved resilience during OpenSearch cluster maintenance or outages
- Better scalability for handling large volumes of updates
- Reduced direct coupling between our application and the OpenSearch cluster
- Enhanced ability to handle backpressure during peak loads
Streamlining Deployments: SAM and Integration Testing
In developing our new microservice and state machines, we leveraged the AWS Serverless Application Model (SAM) framework. While SAM’s benefits are numerous, I want to focus on how we’ve implemented integration testing to ensure robust deployments.
At Grabyo, we prioritize security with weekly releases to address vulnerabilities. This process underscores the importance of thorough integration testing. We’ve created a post-hook process that simulates real data traffic between DynamoDB and OpenSearch during deployments.
Here’s our deployment verification process:
- Write a new entry to the database
- Verify the data in OpenSearch after 5 seconds
- Delete the data from the database
- Confirm data removal from OpenSearch after 5 minutes
If any step fails, the deployment is automatically rolled back. We implement this using SAM’s PostTraffic hook, which executes after the lambda is deployed. In our queue-based architecture, if the process fails, SAM and CodeDeploy roll back the changes, and queued objects are processed later, causing only a minor delay.
It’s worth noting a limitation we encountered with SAM: there’s no built-in hook that runs for every change in a release. Instead, we needed to create a separate hook for each lambda function we wanted to test. With two lambda functions per pipeline, this added some boilerplate to our configuration. While not a major issue, it’s something to be aware of when implementing similar testing strategies.
Here’s the SAM template code for our deployment strategy:
DeploymentPreference:
Type: AllAtOnce
Hooks:
PostTraffic: !Ref PostTrafficHookReplicationDDBStreamProcessorFunction
TriggerConfigurations:
- TriggerName: ReplicationDDBStreamProcessorFunctionDeploymentAlerts
TriggerTargetArn: !Ref ReplicationAlarmTopic
TriggerEvents:
- DeploymentSuccess
- DeploymentFailureKey components:
AllAtOnce: Deploys updates simultaneously, suitable for our queue-based solution.
PostTraffic: Specifies our post-deployment verification hook.
TriggerConfigurations: Sets up deployment status notifications.Looking ahead, we’re considering implementing queue size monitoring to prevent potential issues related to queue overflow.
This approach verifies data integrity specifically during the deployment process, allowing us to quickly identify and address any synchronization issues between DynamoDB and OpenSearch. While not a constant monitoring solution, this deployment-time verification serves as a crucial safeguard for our data pipeline during system updates.
Migration and Disaster Recovery: Building Resilience into Our Search Infrastructure
As we embarked on our journey to upgrade our search infrastructure, we quickly realized that migration and disaster recovery were critical aspects that needed careful consideration. Our move from ElasticSearch to OpenSearch wasn’t just about upgrading software; it was an opportunity to rethink our entire approach to data consistency and recovery.
The Migration Challenge
Migrating from ElasticSearch to OpenSearch presented us with a significant challenge: we needed to transfer all our existing data to the new cluster. This process had to be seamless, ensuring no data loss and minimal downtime for our users.
Leveraging DynamoDB as Our Single Source of Truth
One of the key realizations that shaped our strategy was the role of DynamoDB in our architecture. As our primary database and single source of truth for all search data, DynamoDB offered us a unique advantage. We didn’t need to rely on traditional backup methods for our search cluster because all the necessary data was already stored securely in DynamoDB.
Building a Robust Re-synchronization System
Instead of focusing on backups, we set our sights on creating a system that could efficiently re-synchronize all data between DynamoDB and the OpenSearch cluster. This approach would not only support our migration efforts but also provide a reliable mechanism for disaster recovery.
Our goals for this system were clear:
- Eliminate reliance on scripts or manual processes
- Create a solution that could be easily triggered and monitored
- Ensure scalability to handle our growing data needs
Introducing DR State Machines

To meet these objectives, we decided to leverage AWS Step Functions to build a series of Disaster Recovery (DR) state machines. We created one state machine for each index, designed to perform a complete re-sync of data from DynamoDB to OpenSearch.
Each DR state machine follows these key steps:
- DynamoDB Dump: Create a dump of the required tables from DynamoDB into Amazon S3.
- Data Transformation: Use Amazon Athena to combine the data and generate the correct format for OpenSearch. This step produces a set of new JSON files in S3 containing the final, formatted data.
- Data Insertion: Execute a Lambda function that reads these files and performs batch insertions into the OpenSearch cluster.
The Master DR Runbook
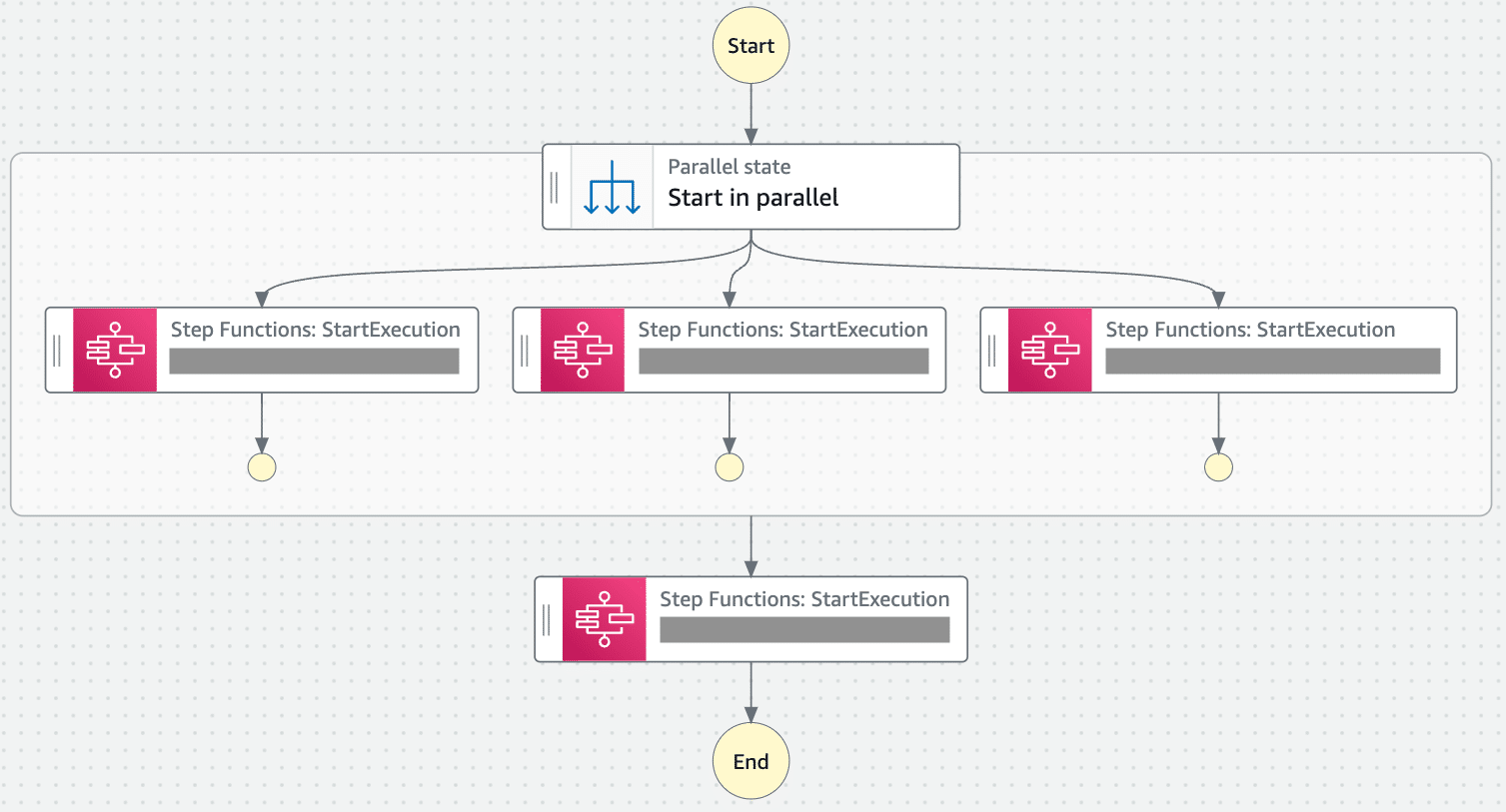
To tie everything together, we created a master state machine that acts as our DR runbook. This state machine can synchronize and parallelize the execution of all individual DR state machines for each index.
The beauty of this approach is its simplicity from an operational standpoint. In the event of a full disaster recovery scenario, an end user only needs to click a button to initiate the entire process. This “one-click” solution significantly reduces the potential for human error and ensures a consistent, repeatable recovery process.
Benefits of Our New Approach
By implementing this system, we’ve gained several key advantages:
- Flexibility: The same process can be used for both migrations and disaster recovery events.
- Scalability: As we add new indexes or our data grows, we can easily adapt our DR state machines to handle the increased load.
- Reliability: By automating the process, we’ve reduced the risk of human error during critical recovery operations.
- Speed: Parallel execution of state machines allows for faster overall recovery times.
- Consistency: Every recovery operation follows the same, tested process, ensuring consistent results.
The Road Not Taken: Technologies We Considered
In the process of upgrading our search infrastructure, we explored several alternatives that, while promising, didn’t quite align with our specific needs:
Amazon OpenSearch Service Zero-ETL initially appeared to be an ideal solution. As a managed service designed to synchronize data between DynamoDB and OpenSearch seamlessly, it promised to simplify our architecture significantly. However, two key issues emerged during our evaluation. First, the pricing model proved problematic. With a minimum charge of $0.25 per hour per DynamoDB table (approximately $182.5 per month), it represented a substantial overcharge for our use case, where most indices are infrequently updated. Our Lambda-based solution, by comparison, operates at a fraction of that cost. Secondly, our system relies on combined indexes that aggregate data from multiple DynamoDB tables, a feature not supported by Zero-ETL at the time of our evaluation.
We also considered AWS Database Migration Service (DMS) and AWS Glue, not for constant data synchronization, but as potential tools for cluster migrations and disaster recovery operations. These services offer robust capabilities for data movement and transformation, which initially seemed well-suited for large-scale data operations. However, we encountered two primary obstacles. Both services require enabling Fine-grained access control in our OpenSearch cluster, necessitating updates to all our cluster clients. Given the infrequent nature of our migration and disaster recovery operations, this added complexity across our entire system was difficult to justify. Additionally, implementing either of these tools would have introduced a new technology stack unfamiliar to most of our team, potentially problematic during critical recovery scenarios where time and reliability are crucial.
Our journey through these technological possibilities proved invaluable in clarifying our priorities. We learned that while feature-rich, managed services can offer significant benefits, they need to align closely with our specific use case, existing infrastructure, and team expertise to be truly effective. The decision-making process reinforced the importance of considering not just the technical capabilities of a solution, but also its impact on our operational costs and team workflow.
As we move forward with our chosen solution, we remain open to reevaluating these technologies as our needs evolve and the services mature. In the dynamic world of cloud infrastructure, maintaining this adaptable mindset is crucial for long-term success.
Wrapping Up: Lessons from Our Search Infrastructure Journey
As we conclude our search infrastructure upgrade saga, we’re excited to share some key takeaways:
- Exploring New Horizons: This project was more than just an upgrade—it was an adventure into new technological territories. We had the opportunity to explore cutting-edge technologies that not only solved our immediate challenges but also equipped us with knowledge that will be invaluable for future projects.
- Learning Through Integration: Our deep dive into integration testing with SAM (Serverless Application Model) was particularly enlightening. We also gained insights into step functions and other technologies that, while not implemented in this project, have expanded our toolkit for future solutions.
- Raising the Bar for Disaster Recovery: Perhaps our proudest achievement is the new standard we’ve set for our disaster recovery processes. We’ve built a solution that significantly reduces complexity while increasing our responsiveness during critical scenarios. The beauty of our new system lies in its simplicity—any engineer on our team can now implement DR procedures with ease, drastically improving our resilience.
While this project may not have revolutionized our entire system, it has certainly added valuable tools to our technical repertoire. We’ve gained practical experience with new technologies and methodologies that will inform our approach to future challenges. As we move forward, we’re looking forward to applying these insights to continually improve Grabyo’s infrastructure.