Alerting Nirvana: How Grabyo Tamed the Notification Beast

The Alerting Challenge: Our Pain Points
Picture this: You’re deep in concentration, working on a complex piece of code, when your screen lights up with a series of alerts. Sound familiar? At Grabyo, we found ourselves facing some common challenges with our alerting system. While our setup was functional, we knew there was room for improvement. Here’s what we were dealing with:
- Alert Volume: Our engineers were receiving a high number of notifications. While many were important, we also had our fair share of false positives and incorrectly prioritized alerts. It was becoming increasingly challenging to distinguish critical issues from minor hiccups.
- Diverse Alert Sources: We had alerts coming from various channels – Slack, email, Amazon SNS, Opsgenie, you name it. Our backend services, databases, Grafana, and AWS X-Ray all contributed to this diverse alert ecosystem. While this diversity had its benefits, it also created some complexity in managing and responding to alerts efficiently.
- Visibility Issues: Some alerts were only reaching specific email inboxes or individual engineers. This sometimes led to important information not being shared as widely as it could be, occasionally hampering our ability to collaborate effectively across teams.
- Inconsistent Definitions: Different teams had developed their own alert languages and priorities over time. This lack of standardization sometimes led to confusion when collaborating on cross-team issues.
- Limited Analytics: We had limited insights into our alert patterns, which made it challenging to systematically improve our alerting system. We knew there was valuable data in our alerts, but we weren’t fully leveraging it.
While these challenges were not crippling our operations, we recognized that addressing them could significantly enhance our efficiency and responsiveness. We saw an opportunity to evolve from a functional alerting system to an exceptional one.
The Alerting Promised Land: Our Must-Have Requirements
After experiencing one too many alert-induced headaches, we knew it was time for a change. We gathered our team and outlined a set of requirements for our ideal alerting system. Here’s what we came up with:
- Noise Reduction: We needed a system capable of differentiating between critical issues and minor hiccups. Only actionable alerts should make it through, and they needed to be properly prioritized.
- Unified Alert Delivery: We envisioned a single, centralized alert delivery system to replace our scattered approach.
- Improved Visibility: Every alert should be visible to all relevant team members, eliminating information silos and fostering collaboration.
- Consistent Alert Definitions: We wanted a standardized approach to defining and setting up alerts across all teams and services.
- Insightful Analytics: We needed clear visibility into our alert patterns to identify problematic areas and prioritize improvements.
- User-Friendly Management: The system should be intuitive, allowing for easy creation, modification, and retirement of alerts.
- Seamless Integration: Our new alerting system needed to integrate smoothly with our existing tools and processes, including our incident management workflow and communication channels.
- Adaptability: As our systems evolve, our alerting needed to keep pace. We wanted the flexibility to adapt our alerts without major overhauls.
- Contextual Information: Alerts should come packed with all the necessary details for quick troubleshooting and resolution.
Alert Priorities

One of our key improvements was establishing a clear, universal system of alert priorities. This ensures all teams interpret urgency and impact consistently. Here’s our streamlined classification:
| Priority | Impact | Urgency |
|---|---|---|
| P1 – Critical | Service downtime | ⚡ Act Now! |
| P2 – High | Service close to downtime | 🕑 First thing – Next working day |
| P3 – Unclassified | Alerts to be moderated | N/A |
| P4 – Low | Service affected | 📅 Next working sprint |
| P5 – Informational | Not an alert | N/A |
Key points about our priority system:
- P1 and P2 alerts demand rapid response, with P1 indicating complete service failure and P2 signifying major degradation.
- P4 and P5 are lower-priority, important for long-term system health but not requiring immediate action.
- P3 serves as our triage category for alerts that need review and proper classification.
This system aids in quick decision-making, proper resource allocation, and setting clear expectations. It also allows us to track alert volumes at each priority level, helping identify areas for improvement.
Our goal isn’t zero alerts, but rather a manageable number of meaningful, actionable notifications. This priority system is crucial in achieving that balance.
The Secret Sauce: Our Key Technology Choices
After careful consideration, we identified two key technologies that would form the backbone of our new alerting system:
Opsgenie: Our Alert Central Station
We chose Opsgenie as the platform where all our alerts would converge. Here’s why it was a game-changer for us:
- Rich Integrations: Opsgenie offers a wide array of integrations for both incoming alerts and outgoing notifications, allowing us to centralize our alerting ecosystem.
- Scalability: The platform is built to handle an enormous volume of alerts, ensuring we won’t outgrow it as our systems expand.
- Cost-Effective: Opsgenie’s pricing model aligned well with our needs, providing excellent value for the features offered.
- Alert Fatigue Reduction: It provides useful tools to help reduce alerting fatigue, such as the ability to set thresholds before triggering notifications.
- Powerful Analytics: Opsgenie’s analytics capabilities give us the insights we need to continually improve our alerting system.
Slack: Our Collaborative Hub
We decided to keep our engineers on Slack for managing alerts, and here’s why:
- Familiarity: Our engineers are already comfortable using Slack for daily communications in our remote work environment.
- Rapid Response: Keeping alerts in Slack enables faster response times, as our team is already actively engaged on the platform.
- Enhanced Visibility: Slack channels increase the visibility of alerts across teams, ensuring that critical information reaches all relevant parties.
- Improved Collaboration: Slack’s features facilitate real-time collaboration between teams when addressing and resolving alerts.
By combining Opsgenie’s robust alerting capabilities with Slack’s collaborative environment, we’ve created an alerting system that addresses our major pain points and meets our key requirements.
Fostering Transparency with Slack
Our Slack channel structure is the secret sauce that brings transparency without drowning our teams in a sea of notifications. Let’s break it down:
The Control Tower: alerts-engineering (P1 & P2)
Imagine a control tower at a busy airport. That’s our alerts-engineering channel.
- Purpose: This channel is the eyes and ears for platform-wide issues. It’s where P1 and P2 alerts from across our entire platform make their grand entrance.
- Who’s Invited: Everyone, but it’s BYOB (Bring Your Own Bandwidth). We’ve made this channel optional, especially for our newer engineers who might not need the full firehose of platform-wide alerts just yet.
Team Channels: Where the Magic Happens
Each team gets two channels, like a mullet – business in the front, party in the back.
- alerts-team-TEAM_NAME
- Purpose: This is where P1 and P2 alerts specific to each team land.
- Who’s Invited: All team members, no exceptions. It’s like your team’s daily standup, but for alerts.
- alerts-team-TEAM_NAME-notifications
- Purpose: The more casual cousin of the above, this channel catches all P4 and P5 alerts for the team.
- Who’s Invited: It’s an open invitation, but attendance is optional. Not everyone needs to know about every successful deployment, right?
Service Channels: For the Collaborative Spirits
Some services are like the office water cooler – everyone gathers around them. For these special cases, we have service-specific channels.
- alerts-service-SERVICE_NAME
- Purpose: All P1 and P2 alerts for a specific service call this channel home.
- Who’s Invited: Anyone interested, no RSVP required.
- alerts-service-SERVICE_NAME-notifications
- Purpose: The P4 and P5 alerts for the service hang out here.
- Who’s Invited: Same as above – come if you’re curious, stay if you’re interested.
This setup allows us to maintain transparency without forcing engineers to join multiple team channels just to stay in the loop on services they’re collaborating on. It’s our way of saying, “Here’s all the info, take what you need.”
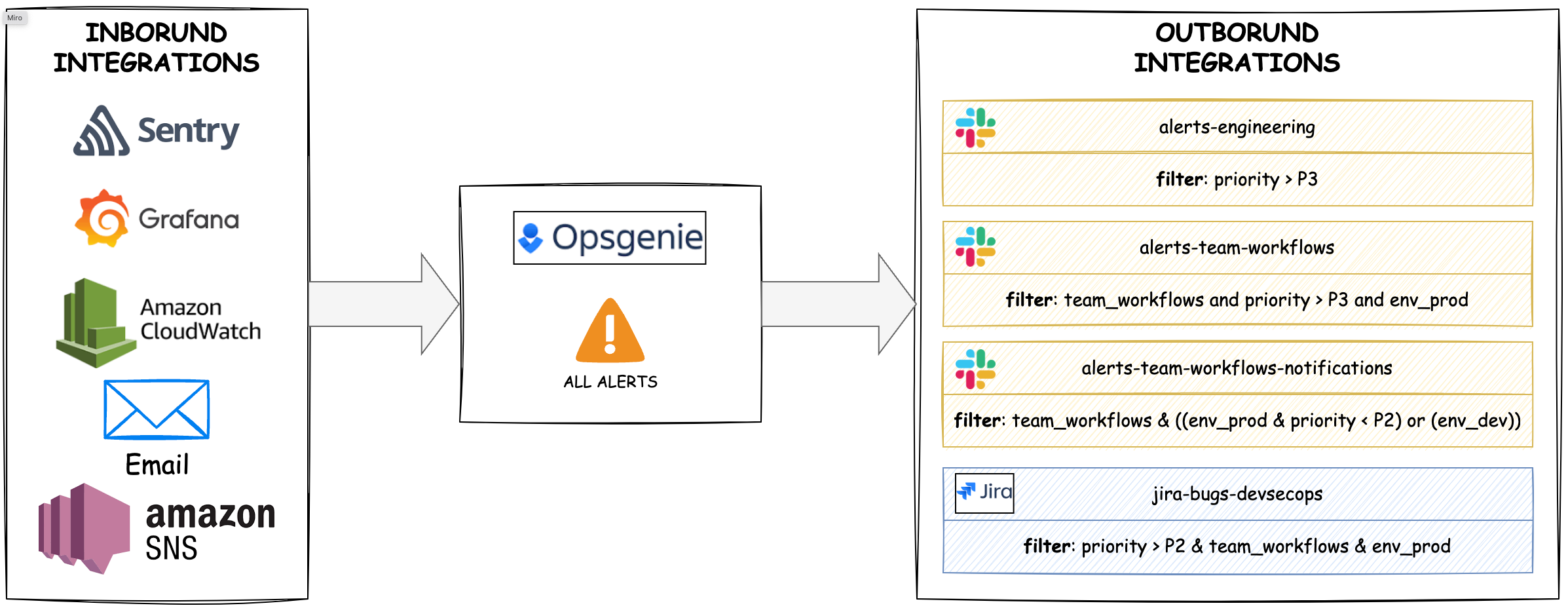
Routing Alerts: The Traffic Control System
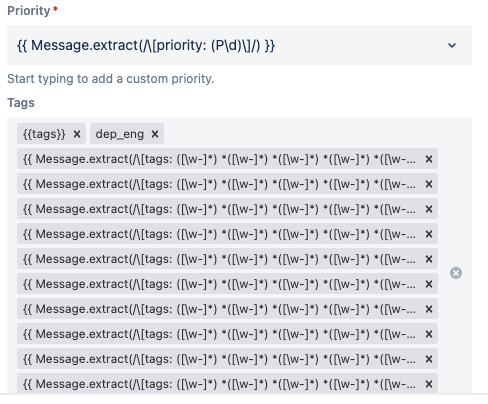
Now, let’s peek under the hood at how we route our alerts. We use tags to determine where an alert should go. To do so, we only need to add a line like this to the body of the alert message:
[priority: P1] [tags: team_devsecops service_deploy_tools env_prod]
Let’s break it down:
- Priority: This is the urgency level of the alert (P1/P2/P3/P4/P5).
- Tags: We can include up to 10 tags to define team, service, and/or environment.
Once this line is included in the alert, Opsgenie takes over. We’ve set up integrations that use regular expressions to convert these lines into the right priority and tags. It’s like having a multilingual translator for our alerts.
The final piece of the puzzle is our outbound integrations for Slack channels. For each alert-dedicated Slack channel, we create a Slack integration in Opsgenie. This integration acts like a bouncer at a club, only letting in alerts with the right priority and team/service tags.

For example, our #alerts-team-platform Slack channel only allows P1 and P2 alerts tagged with team_platform. It’s our way of ensuring that the right alerts reach the right people at the right time.
The Great Migration: Moving Existing Alerts
Unless you’re starting from scratch (lucky you!), you probably have an existing system with alerts flying around like confetti. We certainly did, and we couldn’t just flip a switch to the new system overnight.
So, we got creative. We reserved a specific priority (P3) for all alerts that weren’t following our new conventions. Any alert categorized as P3 and tagged with dep_eng (department_engineering) gets sent to a special Slack channel called alerts-to-moderate.
This channel is like a halfway house for our alerts. All engineering managers keep an eye on it and are responsible for scheduling the necessary sprint work to migrate these alerts to the new system. It’s like spring cleaning, but for our alert system.
During this migration, teams take the time to decide if each alert is still needed and what its new priority should be. It’s a great opportunity to declutter and optimize our alert ecosystem.
Lessons Learned and Future Plans
Our journey to alerting nirvana has taught us valuable lessons and opened up exciting possibilities for the future:
- Centralization is key: By consolidating our alerts into a single platform, we’ve dramatically improved our ability to manage and respond to issues.
- Prioritization matters: Our clear priority system has helped teams quickly identify and address the most critical issues first.
- Transparency fosters collaboration: Our Slack channel structure has increased visibility across teams, leading to faster problem-solving and better cross-team cooperation.
- Continuous improvement is crucial: The analytics provided by Opsgenie have become an indispensable tool in our alerting ecosystem. They allow us to:
- Stay on top of our Key Performance Indicators (KPIs) for alerts
- Quickly identify and address new sources of alert spam
- Track the effectiveness of our alert reduction efforts
- Make data-driven decisions about our alerting strategy
- Migration takes time: Our approach of using P3 alerts as a transitional category has allowed for a smoother migration process, giving teams the time to thoughtfully review and update their alerts.
Looking ahead, we plan to:
- Further refine our alert categories based on the insights gained from Opsgenie’s analytics
- Explore advanced features of Opsgenie to enhance our alerting capabilities
- Continue to educate teams on best practices for creating and managing alerts
- Regularly review and optimize our Slack channel structure to ensure it meets our evolving needs
By staying vigilant and leveraging the power of analytics, we’re committed to maintaining an efficient, effective alerting system that evolves with our organization.
In conclusion, our journey from alert hell to alerting nirvana wasn’t just about implementing new tools. It was about rethinking our entire approach to alerts, from how we generate them to how we consume them. By centralizing our alerts in Opsgenie, leveraging Slack’s collaborative power, and thoughtfully structuring our communication channels, we’ve created a system that keeps us informed without overwhelming us.
Remember, the perfect alerting system isn’t about seeing everything – it’s about seeing the right things at the right time. And for us at Grabyo, that’s made all the difference.