Optimising monitoring costs with Timestream and Grafana

Overview
Establishing a robust streaming platform necessitates extensive vigilance across various domains, encompassing ingestion, processing, visualization, and more.
As the platform expanded over time, the necessity for a centralized monitoring tool grew concurrently. To accommodate this growth, we integrated additional monitoring and alerting tools into our system. However, after a few years, it became apparent that our data was dispersed across multiple storage solutions. Furthermore, the third-party tool we employed encountered significant rate-limiting issues due to the substantial volume of data we managed. This predicament swiftly became unmanageable regarding operational expenses and the resources devoted to maintenance. The influx of clients and services further exacerbated the need for incorporating additional metrics into the existing array of tools.
Current setup
Our previous setup involved three distinct approaches for collecting and visualizing server, application, and custom metrics. These methods encompass two third-party applications and the utilization of CloudWatch. Allow me to delve into each of these approaches in more detail:
- Server Density for server monitoring: Server Density requires the installation of an agent on our servers. This agent automatically transmits the collected data to the vendor’s website, where we can subsequently visualize all the metrics. However, one of the major disadvantages of Server Density is its pricing model where we need to pay per EC2 server ever spawned. This was not cost-effective for us as we usually spawn up and down servers all the time.
- Librato for Metric Publishing: Librato is used for publishing metrics at regular intervals from all our servers and applications to an endpoint provided by the vendor. This approach allows us to visualize the metrics through their website. Unlike the previous application, this solution does not limit the number of nodes or metrics. However, we encountered challenges concerning request throttling. As the number of applications and servers increased, the frequency of these throttling occurrences escalated, hindering the smooth flow of data and impeding real-time monitoring capabilities.
- CloudWatch: Due to the aforementioned limitations and challenges posed by third-party applications, we explored using CloudWatch as an alternative. While CloudWatch provided robust metering, alerting, and visualization capabilities, we discovered that its cost was prohibitively high for our requirements. Consequently, we relied on three separate tools, each serving a specific purpose of metering, alerting, and visualization.
In summary, our previous monitoring setup involved a combination of applications with specific limitations, such as node restrictions, request throttling and high costs. Although this configuration enabled us to gather the necessary metrics, it has led to a fragmented approach, with each tool serving a distinct function.
Additionally, it is worth noting that all three of the applications we have employed for metering, alerting, and visualization purposes come with significant expenses. The costs associated with these tools added to our operational budget, further emphasizing the need for a more cost-effective and streamlined monitoring solution. The financial burden imposed by these applications underscored the importance of finding a comprehensive and affordable alternative that could consolidate our monitoring efforts while still meeting our requirements effectively.
Requirements
We had several crucial requirements for our monitoring solution, each warranting detailed consideration:
- Real-time server metric reporting: It was paramount for us to gather and report server metrics, such as CPU utilization, memory usage, disk space, and more, at a high frequency of every 1 minute. This level of granularity allowed us to closely monitor the performance and resource utilization of our servers, enabling timely identification of any bottlenecks or anomalies.
- Custom metric creation: Flexibility was a key factor in our monitoring needs. We required the ability to create and track custom metrics tailored to our specific requirements. This capability allowed us to gain deeper insights into the performance and health of our streaming platform beyond the standard predefined metrics.
- Anomaly detection and service failure monitoring: Ensuring the continuous availability and reliability of our services was a top priority. We sought a monitoring solution that could proactively detect anomalies and promptly notify us during service failures. By promptly addressing such incidents, we could minimize downtime and maintain a high-quality streaming experience for our clients.
- Efficient data querying: Easy accessibility to monitoring data was essential for timely analysis and decision-making. We needed a solution that offered convenient and efficient querying capabilities, enabling us to extract relevant information quickly and effectively. This capability allowed us to respond promptly to emerging issues or perform comprehensive performance evaluations.
- In-house extensibility: To maintain flexibility and adaptability for future requirements, we aimed to adopt an in-house solution that provided us with the freedom to extend its functionalities as needed. By having control over the development and customization of the monitoring tool, we could align it precisely with our evolving needs and seamlessly integrate it into our existing infrastructure.
- Low maintenance overhead: Recognizing the importance of resource optimization, we desired a monitoring solution that required minimal ongoing maintenance. Specifically, we aimed to avoid excessive scaling challenges, burdensome version updates, and complex operational procedures that would otherwise consume valuable time and resources. By minimizing the maintenance overhead, we could focus our efforts on enhancing the streaming platform’s performance and delivering an exceptional user experience.
- Cost-effectiveness: While fulfilling our comprehensive monitoring requirements, we also aimed to maintain cost efficiency. It was essential to ensure that the chosen solution would not exceed our existing budget significantly. This consideration allowed us to balance acquiring an advanced monitoring system and optimizing costs, ensuring the best value for our investment.
By addressing these diverse requirements comprehensively, we established a professional, robust, and cost-effective monitoring solution that catered to the evolving needs of our streaming platform.
Upon recognizing the need for a centralized and efficient solution, we determined that utilizing a time series database, such as AWS Timestream, in conjunction with a tool for data querying and visualization, would be the most suitable course of action.
A time series database is specifically designed to process, and index data points in chronological order, making it ideal for managing time-dependent datasets. Typically, time series databases find applications in diverse domains, ranging from financial stock markets and server measurements to IoT devices, sensors, and weather forecasts.
To identify the most appropriate solution for our requirements, we conducted an in-depth evaluation of available options, including AWS Timestream, Grafana, Cloudwatch, and other third-party applications. Our research conclusively demonstrated that combining AWS Timestream with Grafana provided the greatest potential for cost savings, with potential cost reductions of up to four times compared to AWS CloudWatch.
Thus, the concept of establishing a centralized platform for visualizing all metrics across our entire streaming platform was conceived. Following a few days dedicated to building a proof-of-concept (POC) and engaging in thorough deliberations, we made the informed decision to leverage AWS Timestream and AWS Managed Grafana.
Timestream
Timestream is a serverless time series database provided by AWS, and it was announced in 2018 at re:Invent. Amazon Timestream would offer a 1000 times faster query performance and a reduction of costs by a factor of ten as compared to relational databases. It also makes it easier to handle trillions of time series data with high performance while charging almost a tenth of the cost of the traditional relational database. Also, being a serverless service means you don’t need to worry about scaling, patching or availability. Everything is done automatically by AWS.
Timestream is designed to manage the lifecycle of time series data automatically, and it offers two data stores – the in-memory store and a cost-effective magnetic store, and it supports configuring table-level policies to transfer data across those stores automatically. Incoming writes will be sent to the memory store, where data is optimized for writes and for reads performed around the current time. When the main time frame you configured at the table level has passed, the data will be automatically moved from the memory store to the magnetic store.
You can configure the magnetic store data retention policy at the table level, and that will specify the time threshold where the data will expire. Once the data moves to the magnetic store, it is reorganized into a format that is highly optimized for large-volume data reads. When the data exceeds the time range defined for the magnetic store retention policy, it is automatically removed. Data written for late arrival data are directly written into the magnetic store.
Querying the data in Timestream has never been easier – you can use SQL to query data in Timestream to retrieve time series data from one or more tables. Timestream’s SQL also supports built-in functions for time series analytics.
Timestream has multiple integrations with different AWS and third-party tools and services. For data ingestion, it integrates with Kinesis, Lambda, IoT Core, SageMaker, Telegraf, etc. For querying and visualization, it integrates with QuickSight, Grafana, and most of the applications and tools that support JDBC connections(i.e. SQL Workbench).
Grafana
Grafana is an open-source analytics interactive visualization web application that you can use to visualize your data sources. It provides charts, graphs, and alerts for the web when connected to supported data sources. Grafana is very easy to install and use with Timestream or any other data sources like Prometheus, MySQL, InfluxDB, Graphite, ElasticSearch, Splunk, etc.
We seek an auto-scaling, low-maintenance service with high availability. Grafana, an open-source tool, became a fully managed AWS service just as we planned our monitoring solution. AWS Managed Grafana offers native integration with AWS Services like Timestream and Cloudwatch, is fully overseen by AWS, and supports AWS Single Sign-On for authentication.
The price is very reasonable at this time, and we expect that to decrease over time. You pay only for what you use, based on an active user license per workspace. An Amazon Managed Grafana Editor license costs $9 per active editor or administrator user per workspace and provides the user with administrative permissions for managing workspace users, creating and managing dashboards and alerts, and assigning permissions to access data sources. For customers who need only view access, an Amazon Managed Grafana Viewer license costs $5 per active user per workspace and provides the user with view-only access to the Amazon Managed Grafana workspace. Users with view-only access can view dashboards, alerts, and query data sources but perform no other actions on the workspace. Grafana API keys are associated with an API user license and can be granted Administrator, Editor, or Viewer permissions.
Setup
We knew we wanted to monitor server metrics every minute and also have application metrics. For that, we installed Telegraf on our EC2 instances and used the integration plugin in the config file. We also ensured we have the right permissions to ingest Timestream from these EC2 instances by changing the policy in the IAM roles to enable write access to Timestream. Also, the application uses the AWS SDK to ingest data into Timestream.
To set up Telegraf, you will need to go to the outputs plugin and add your database and table details:
[[outputs.timestream]] region = "eu-west-1" database_name = "testDB" ## The database must exist prior to starting Telegraf. describe_database_on_start = true ## Specifies if the plugin should describe the Timestream database upon starting to validate if it has access necessary permissions, connection, etc., as a safety check. mapping_mode = "single-table" ## The mapping mode specifies how Telegraf records are represented in Timestream, different tables for each measurement or one single table for all measurements single_table_name = "testTable" ## Specifies the Timestream table where the metrics will be uploaded. Only valid and required for mapping_mode = "single-table" single_table_dimension_name_for_telegraf_measurement_name = "namespace" create_table_if_not_exists = false ## Specifies if the plugin should create the table, if the table do not exist.
You have some options to create the table if it doesn’t exist and set the memory store and magnetic store retention period.
In order to visualize the data, you will need to go to your Grafana Managed console and create a new workspace, and follow the steps, or if you already have a workspace created, click on that workspace to access it.
Go ahead and create a data source by selecting the AWS Data Sources tab and choosing Timestream from the Service field. From there, follow the steps to point your data source to your Timestream, and you are ready to use it.
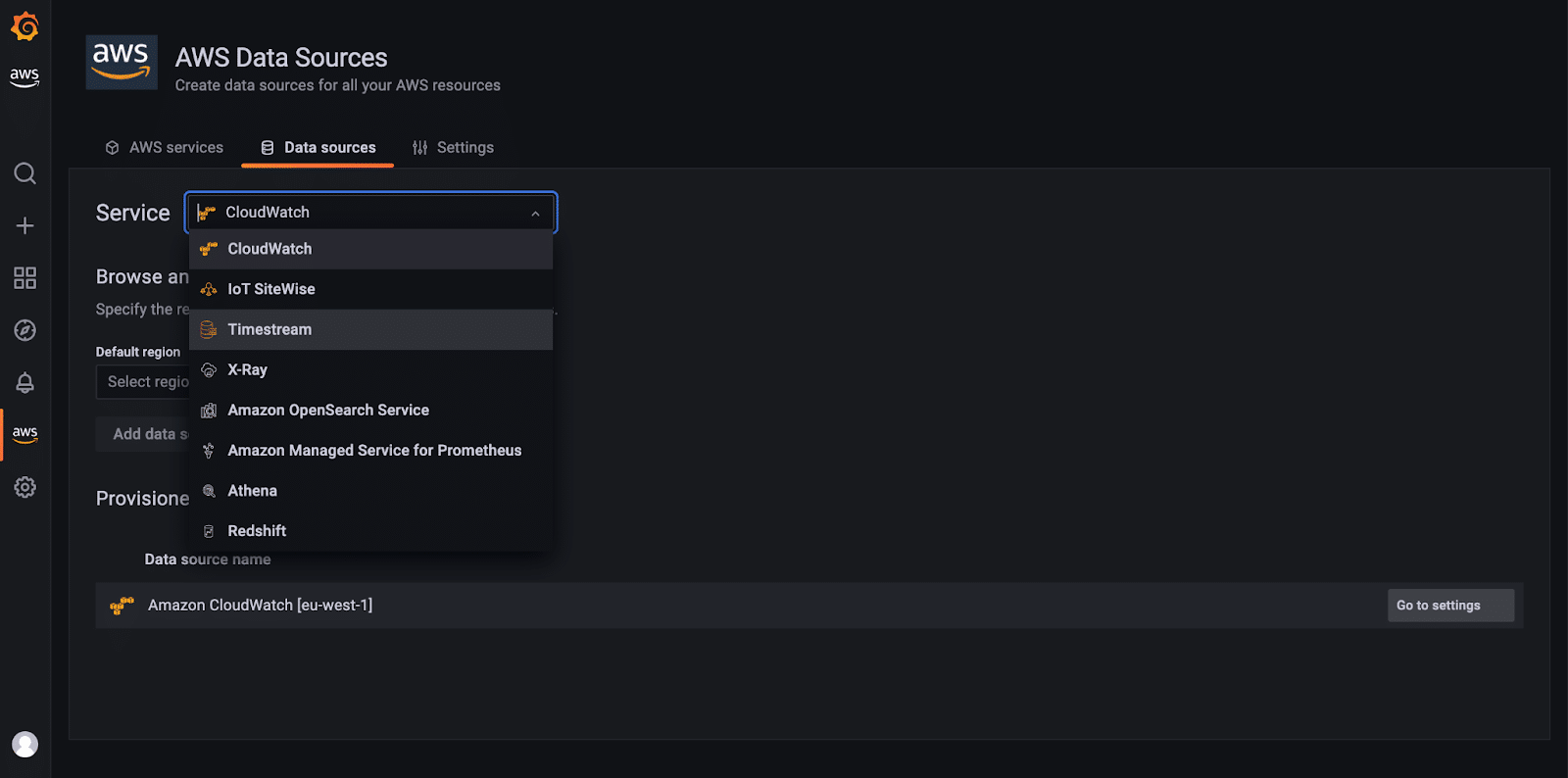
Next, we will try and visualize the CPU Idle Usage, and for that, we will need to click on the + tab to create a new Dashboard and select Add Panel.
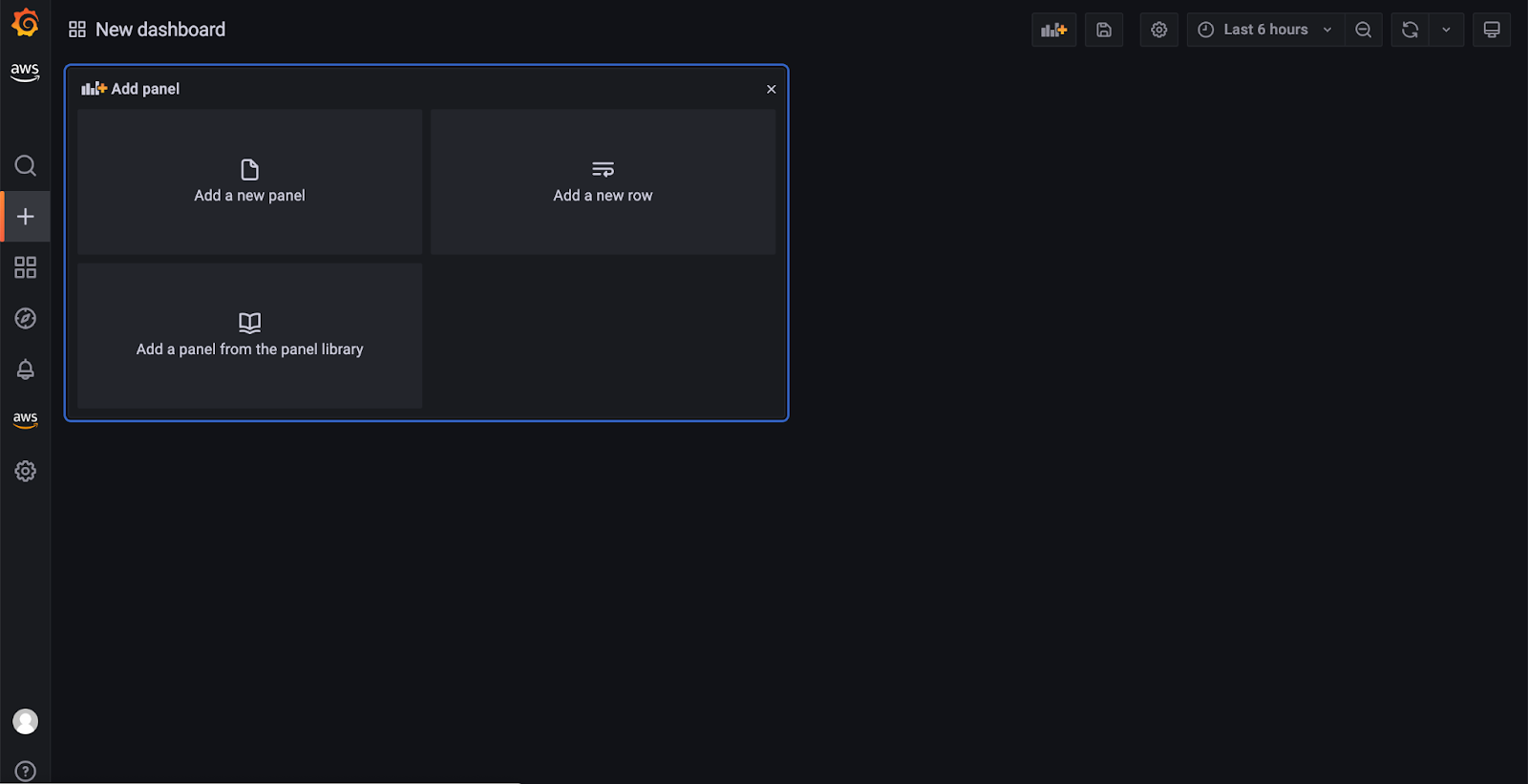
On the panel page, you can select your database, table, and measure name – in our case, testDB, testTable, respectively usage_idle and insert your SQL command.
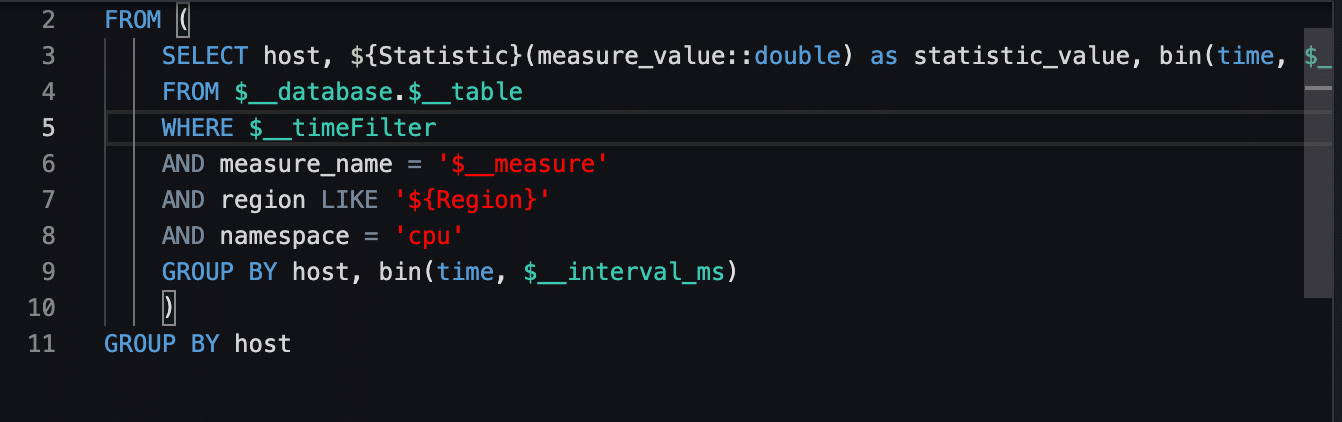
The fields that start with $ are variables that you set at the panel level (like database, table, and measure), when you select the time frame you want to visualize the data (timeFilter – the period you select to view in the panel, interval_ms – the aggregated period, this is automatically calculated by Grafana when you select the time period), when you create your data source(Region, etc.), or when you create your own custom variables that you can add to your own panel.
Grafana is a very powerful tool that comes with multiple settings, so I will recommend playing with different fields and seeing what will be the best one for your use case.
Now, your graph should look something like this:
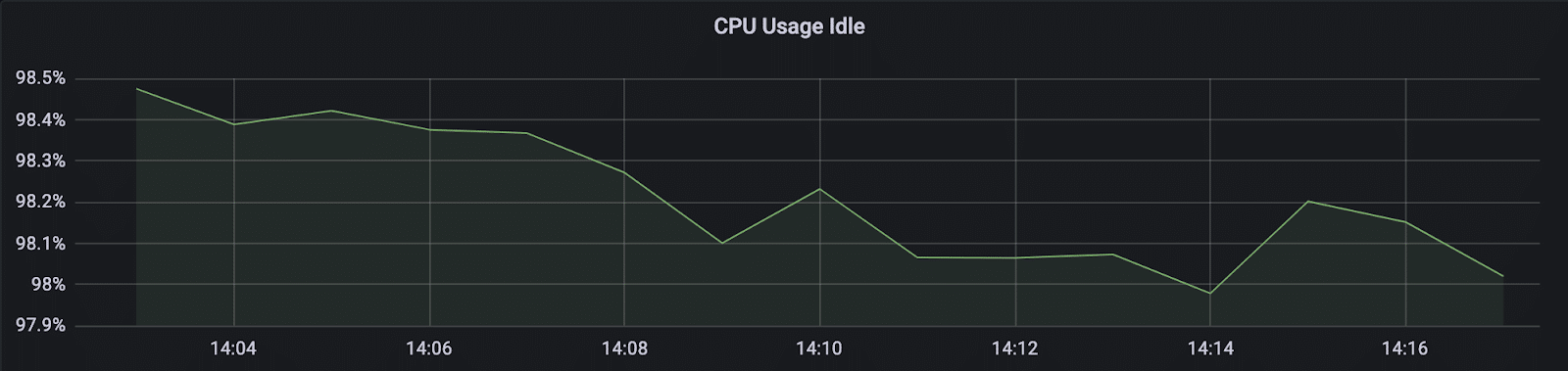
You can create multiple panels in a dashboard and repeat the same steps for all the data you want to visualize, and you will end up with a very nice dashboard from where you can see all your server metrics.
Good luck! 🙂
We’re hiring!
We’re looking for talented engineers in all areas to join our team and help us to build the future of broadcast and media production.